
Có thể các bạn đã biết đến tính năng Code Interpreter của ChatGPT và khả năng phân tích dữ liệu rất mạnh mẽ của AI này, nhưng liệu các bạn đã sử dụng nó hiệu quả chưa? Bài viết này sẽ trình bày một case study về việc sử dụng ChatGPT để phân tích một dataset phim điện ảnh lớn, nhằm minh họa cách mà người dùng có thể tương tác với ChatGPT để khai thác tối đa tiềm năng của dữ liệu.
Bắt Đầu Với Dữ Liệu
Khi tiếp cận một tập dữ liệu lớn, việc đầu tiên cần làm là hiểu rõ cấu trúc và nội dung của nó.
Bạn có thể download dataset này tại đây. Dataset này bao gồm metadata của 45,000 phim điện ảnh được phát hành trước tháng 07/2017. Tập dữ liệu này có dung lượng hơn 200MB, chứa nhiều thông tin quan trọng như tiêu đề, ngày phát hành, doanh thu, ngân sách, và các thể loại phim.
Bước đầu tiên là yêu cầu ChatGPT giúp phân tích sơ bộ và gợi ý những bước tiếp theo có thể thực hiện với tập dữ liệu này.
Yêu Cầu ChatGPT Phân Tích Sơ Bộ Và Gợi Ý
Khi bắt đầu, tôi đã yêu cầu ChatGPT giải nén tập tin và cung cấp một cái nhìn tổng quan về các tệp tin bên trong. Kết quả cho thấy có nhiều tệp CSV chứa các thông tin khác nhau như:
- credits.csv: Chứa thông tin về dàn diễn viên và đoàn làm phim.
- keywords.csv: Chứa các từ khóa liên quan đến phim.
- links.csv và links_small.csv: Chứa các liên kết đến các nguồn tài nguyên bên ngoài như IMDb.
- movies_metadata.csv: Chứa metadata về phim như tiêu đề, ngày phát hành, thể loại, v.v.
- ratings.csv và ratings_small.csv: Chứa thông tin về đánh giá của người xem.
Dựa trên phân tích sơ bộ này, ChatGPT đã gợi ý một số hướng phân tích tiềm năng như phân tích độ phổ biến của phim qua thời gian, xu hướng các thể loại phim theo từng giai đoạn, và mối tương quan giữa ngân sách và doanh thu của phim.
Việc này là rất cần thiết vì nó chứng minh rằng ChatGPT đã có thể giải nén tập tin và truy cập vào dữ liệu của nó để phân tích.

Đặt Câu Hỏi Và Lọc Dữ Liệu
Tiếp theo, tôi quyết định bắt đầu với việc phân tích độ phổ biến của phim qua thời gian và xu hướng các thể loại phim. Tôi đã yêu cầu ChatGPT lọc và chuẩn bị dữ liệu từ tệp movies_metadata.csv.
Dựa vào yêu cầu trên, ChatGPT đã tự phân tích và chạy code python để tiến hành các bước cho ra kết quả bao gồm việc chuyển đổi định dạng ngày phát hành, chuyển đổi các giá trị ngân sách và doanh thu sang dạng số, và trích xuất năm từ ngày phát hành để dễ dàng phân tích theo thời gian.
ChatGPT đã thực hiện việc này một cách nhanh chóng và cung cấp dữ liệu đã được làm sạch, sẵn sàng cho các bước phân tích tiếp theo. Tôi cũng yêu cầu ChatGPT tách các thể loại phim thành từng dòng riêng biệt để có thể phân tích chi tiết hơn về xu hướng các thể loại.
Phân Tích Các Mối Tương Quan Trong Dữ Liệu
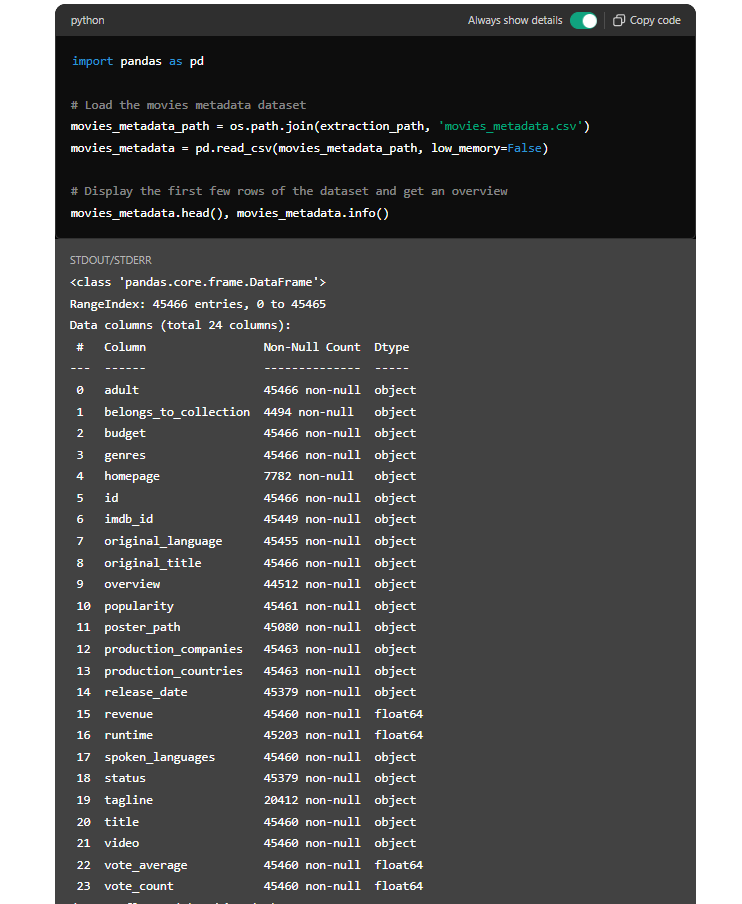
Với dữ liệu đã được làm sạch, tôi tiến hành yêu cầu ChatGPT phân tích mối tương quan giữa các yếu tố như độ phổ biến, doanh thu, và ngân sách của phim. Một trong những câu hỏi quan trọng là liệu có mối tương quan mạnh giữa ngân sách và doanh thu của phim hay không.

Yêu Cầu ChatGPT Phân Tích Và Vẽ Biểu Đồ
Sau khi yêu cầu phân tích tương quan giữa ngân sách và doanh thu, ChatGPT đã sử dụng các công cụ như pandas và matplotlib để tính toán và vẽ biểu đồ. Kết quả cho thấy có một mối tương quan khá mạnh giữa ngân sách và doanh thu, với hệ số tương quan khoảng 0.77. Điều này gợi ý rằng những bộ phim có ngân sách cao thường có xu hướng đạt được doanh thu cao.
Phân Tích Chi Tiết Theo Thể Loại
Ngoài ra, tôi cũng yêu cầu ChatGPT phân tích chi tiết hơn về mối tương quan này theo từng thể loại phim. Kết quả cho thấy các thể loại như Hành Động, Phiêu Lưu, và Hoạt Hình có mối tương quan rất mạnh giữa ngân sách và doanh thu. Điều này giúp xác định rằng các thể loại phim này thường đạt được doanh thu cao hơn khi được đầu tư nhiều về mặt ngân sách.
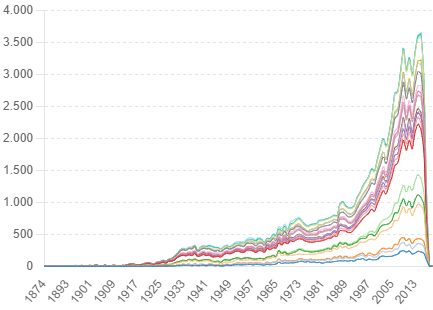
Phân tích xu hướng các thể loại phim cho thấy sự thay đổi đáng kể trong sự phổ biến của các thể loại theo thời gian. Ví dụ, các thể loại như Hành Động và Phiêu Lưu luôn có một vị trí vững chắc trong suốt các thập kỷ, trong khi các thể loại như Khoa Học Viễn Tưởng và Siêu Anh Hùng đã trở nên phổ biến hơn trong những năm gần đây.
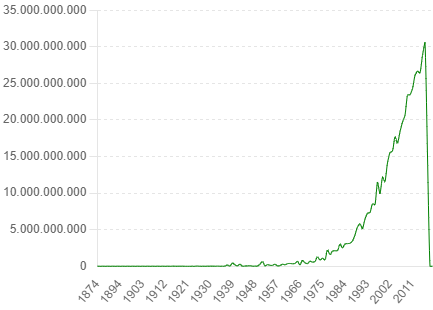
Phân tích tổng doanh thu của phim qua các năm cho thấy một xu hướng tăng trưởng đều đặn, với những năm có sự tăng vọt đáng kể. Điều này có thể được giải thích bởi sự phát triển của ngành công nghiệp điện ảnh, với sự ra mắt của nhiều bộ phim bom tấn và sự mở rộng của thị trường toàn cầu.
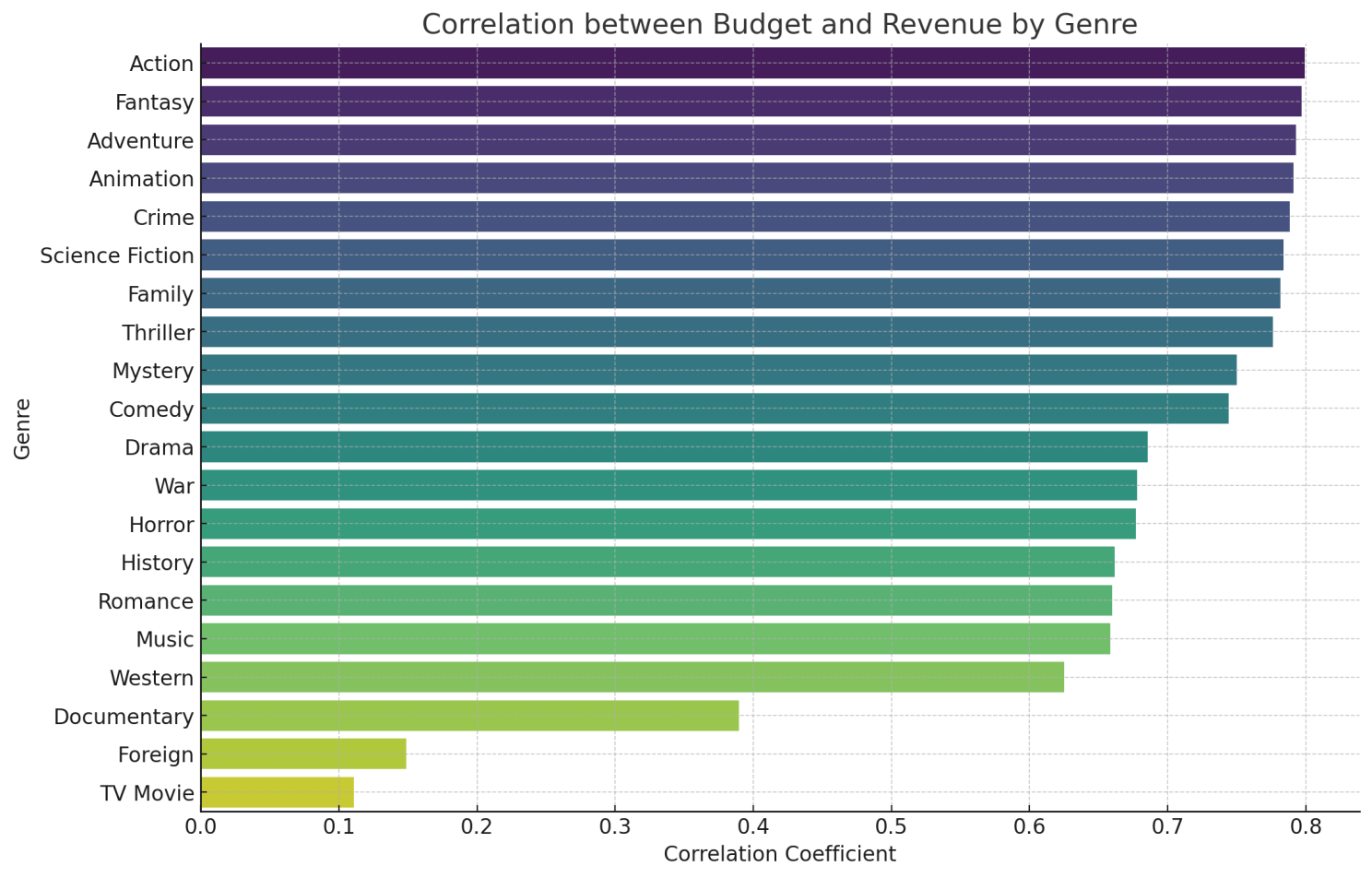
Phân tích mối tương quan giữa ngân sách và doanh thu của phim cho thấy một mối tương quan mạnh (hệ số tương quan khoảng 0.77). Điều này cho thấy rằng những bộ phim được đầu tư nhiều về ngân sách thường có xu hướng đạt doanh thu cao hơn.
Lưu Lại Thành Các Định Dạng File
Một phần quan trọng trong quá trình phân tích dữ liệu là lưu lại kết quả dưới các định dạng file phù hợp để dễ dàng chia sẻ và xem xét sau này. Tôi đã yêu cầu ChatGPT lưu lại các phân tích và biểu đồ dưới dạng file CSV và hình ảnh. Điều này giúp tôi có thể dễ dàng truy cập và trình bày kết quả với các bên liên quan.
Bạn cũng có thể yêu cầu ChatGPT lưu lại các biểu đồ dưới dạng ảnh, hoặc thậm chí tổng hợp toàn bộ phân tích trước đó và lưu lại dưới dạng một bài thuyết trình Powerpoint.
Đối với những nhà lập trình, bạn có thể yêu cầu ChatGPT viết code giúp tự động hóa một phần công việc. Dưới đây là ví dụ về code tạo bài thuyết trình từ dataset, sử dụng Python:
import pandas as pd
import matplotlib.pyplot as plt
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image
from reportlab.lib.styles import getSampleStyleSheet
# Step 1: Generate the Visualizations
def create_visualizations():
# Load the dataset
movies_metadata = pd.read_csv('path/to/movies_metadata.csv', low_memory=False)
# Clean and process the data
movies_metadata['release_date'] = pd.to_datetime(movies_metadata['release_date'], errors='coerce')
movies_metadata['popularity'] = pd.to_numeric(movies_metadata['popularity'], errors='coerce')
movies_metadata['revenue'] = pd.to_numeric(movies_metadata['revenue'], errors='coerce')
movies_metadata['budget'] = pd.to_numeric(movies_metadata['budget'], errors='coerce')
movies_metadata['release_year'] = movies_metadata['release_date'].dt.year
movies_metadata = movies_metadata.dropna(subset=['release_year'])
# Popularity Over Time
popularity_over_time = movies_metadata.groupby('release_year')['popularity'].mean().reset_index()
plt.figure(figsize=(10, 6))
plt.plot(popularity_over_time['release_year'], popularity_over_time['popularity'], marker='o')
plt.title('Average Movie Popularity Over Time')
plt.xlabel('Year')
plt.ylabel('Average Popularity')
plt.grid(True)
plt.savefig('popularity_over_time.png')
plt.close()
# Revenue Over Time
revenue_over_time = movies_metadata.groupby('release_year')['revenue'].sum().reset_index()
plt.figure(figsize=(10, 6))
plt.plot(revenue_over_time['release_year'], revenue_over_time['revenue'], marker='o', color='green')
plt.title('Total Movie Revenue Over Time')
plt.xlabel('Year')
plt.ylabel('Total Revenue')
plt.grid(True)
plt.savefig('revenue_over_time.png')
plt.close()
# Genre Trends
import ast
movies_metadata['genres'] = movies_metadata['genres'].apply(lambda x: ast.literal_eval(x) if pd.notnull(x) else [])
movies_metadata = movies_metadata.explode('genres')
movies_metadata['genre_name'] = movies_metadata['genres'].apply(lambda x: x['name'] if isinstance(x, dict) else None)
genre_trends = movies_metadata.groupby(['release_year', 'genre_name']).size().reset_index(name='count')
genre_pivot = genre_trends.pivot(index='release_year', columns='genre_name', values='count').fillna(0)
genre_pivot.plot(kind='area', stacked=True, figsize=(14, 8), cmap='tab20')
plt.title('Trends in Movie Genres Over Time')
plt.xlabel('Year')
plt.ylabel('Number of Movies')
plt.legend(title='Genres', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.savefig('genre_trends.png')
plt.close()
# Budget vs Revenue Correlation
budget_revenue_data = movies_metadata.dropna(subset=['budget', 'revenue'])
plt.figure(figsize=(10, 6))
plt.scatter(budget_revenue_data['budget'], budget_revenue_data['revenue'], alpha=0.5)
plt.title('Correlation between Budget and Revenue')
plt.xlabel('Budget')
plt.ylabel('Revenue')
plt.grid(True)
plt.savefig('budget_revenue_correlation.png')
plt.close()
# Genre-Specific Budget vs Revenue Correlation
genre_correlation = budget_revenue_data.groupby('genre_name').apply(lambda x: x['budget'].corr(x['revenue'])).reset_index()
genre_correlation.columns = ['genre_name', 'correlation']
genre_correlation = genre_correlation.dropna().sort_values(by='correlation', ascending=False)
plt.figure(figsize=(12, 8))
plt.barh(genre_correlation['genre_name'], genre_correlation['correlation'], color='skyblue')
plt.title('Correlation between Budget and Revenue by Genre')
plt.xlabel('Correlation Coefficient')
plt.ylabel('Genre')
plt.grid(True)
plt.savefig('genre_specific_correlation.png')
plt.close()
create_visualizations()
# Step 2: Generate the PDF Report
def create_pdf_report():
doc = SimpleDocTemplate("movie_analysis_report.pdf", pagesize=letter)
styles = getSampleStyleSheet()
story = []
# Title
story.append(Paragraph("Movie Data Analysis Report", styles['Title']))
story.append(Spacer(1, 12))
# Introduction
intro_text = """
This report presents an analysis of a large movie dataset using ChatGPT for various tasks including data cleaning,
correlation analysis, and visualization. The dataset contains information on movies, their budgets, revenues,
popularity, and genres. The following sections detail the findings and visualizations generated during the analysis.
"""
story.append(Paragraph(intro_text, styles['BodyText']))
story.append(Spacer(1, 12))
# Popularity Over Time
story.append(Paragraph("Average Movie Popularity Over Time", styles['Heading2']))
story.append(Image('popularity_over_time.png', width=500, height=300))
story.append(Spacer(1, 12))
# Revenue Over Time
story.append(Paragraph("Total Movie Revenue Over Time", styles['Heading2']))
story.append(Image('revenue_over_time.png', width=500, height=300))
story.append(Spacer(1, 12))
# Genre Trends
story.append(Paragraph("Trends in Movie Genres Over Time", styles['Heading2']))
story.append(Image('genre_trends.png', width=500, height=300))
story.append(Spacer(1, 12))
# Budget vs Revenue Correlation
story.append(Paragraph("Correlation between Budget and Revenue", styles['Heading2']))
story.append(Image('budget_revenue_correlation.png', width=500, height=300))
story.append(Spacer(1, 12))
# Genre-Specific Budget vs Revenue Correlation
story.append(Paragraph("Correlation between Budget and Revenue by Genre", styles['Heading2']))
story.append(Image('genre_specific_correlation.png', width=500, height=300))
story.append(Spacer(1, 12))
# Conclusion
conclusion_text = """
The analysis reveals significant trends and correlations within the movie dataset. Higher budgets tend to correlate
with higher revenues, particularly within genres such as Action, Adventure, and Animation. Additionally, the
popularity and revenue trends over time provide insights into the evolving dynamics of the movie industry.
"""
story.append(Paragraph(conclusion_text, styles['BodyText']))
story.append(Spacer(1, 12))
doc.build(story)
create_pdf_report()Luôn Luôn Chú Ý Tự Mình Kiểm Tra Kết Quả
Mặc dù ChatGPT là một công cụ mạnh mẽ, một trong những bài học quan trọng là luôn luôn tự mình kiểm tra kết quả. Việc này bao gồm kiểm tra lại các bước xử lý dữ liệu, xác nhận tính chính xác của các phân tích và biểu đồ. Điều này giúp đảm bảo rằng các kết quả phân tích là đáng tin cậy và không có lỗi sai sót.
Bạn luôn phải chịu trách nhiệm hoàn toàn cho tất cả những gì ChatGPT tạo ra theo yêu cầu của bạn. Luôn luôn kiểm tra kĩ tính xác thực của kết quả từ ChatGPT trước khi công bố ra bên ngoài. Không bao giờ được tin tưởng và dựa dẫm 100% vào kết quả từ AI.
Lợi Ích
- Tiết Kiệm Thời Gian: ChatGPT giúp tự động hóa nhiều bước trong quá trình phân tích dữ liệu, từ làm sạch dữ liệu đến tạo các biểu đồ và tính toán các mối tương quan.
- Dễ Sử Dụng: Người dùng không cần phải là chuyên gia lập trình hay phân tích dữ liệu để có thể sử dụng ChatGPT hiệu quả. Chỉ cần đặt câu hỏi và hướng dẫn cụ thể, ChatGPT có thể thực hiện các tác vụ phức tạp.
- Tính Linh Hoạt: ChatGPT có thể xử lý nhiều loại dữ liệu khác nhau và thực hiện nhiều loại phân tích, từ phân tích thống kê cơ bản đến các phân tích phức tạp hơn.
Thách Thức
- Kiểm Soát Chất Lượng Dữ Liệu: Dữ liệu đầu vào cần được chuẩn bị kỹ lưỡng để đảm bảo rằng các phân tích sau này chính xác và đáng tin cậy.
- Hiểu Biết Về Kết Quả: Mặc dù ChatGPT có thể thực hiện các phân tích phức tạp, người dùng cần có kiến thức cơ bản về phân tích dữ liệu để hiểu và đánh giá kết quả.
- Kiểm Tra Lại Kết Quả: Luôn cần phải kiểm tra lại các kết quả mà ChatGPT đưa ra để đảm bảo rằng không có sai sót và các kết quả là hợp lý.
Tìm hiểu thêm về sản phẩm Bí Kíp ChatGPT của Cường Anh!
Kết Luận
Sử dụng ChatGPT để phân tích dữ liệu là một phương pháp mạnh mẽ và hiệu quả, nhưng cũng đòi hỏi sự tương tác và kiểm tra kỹ lưỡng từ người dùng. Khả năng đặt câu hỏi đúng và kiểm tra kết quả là yếu tố then chốt để tận dụng tối đa tiềm năng của công cụ này. Với sự kết hợp giữa sức mạnh của AI và hiểu biết của con người, quá trình phân tích dữ liệu có thể trở nên nhanh chóng và chính xác hơn bao giờ hết.







Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.